Open-Source Integration Will Give You Super Powers


Science is hard - we should automate it. But automation integration takes forever. And the more we delay automation, the harder the science gets.
Why is this all so hard?
First, it takes a long time - and sometimes is impossible - to bring together multiple different pieces of equipment necessary to conduct an experiment. For instance, if I want to measure population statistics in a growing biological culture, I need to find a way for a bioreactor to sample into a flow cytometer. These machines are both highly specialized and weren't built with each other in mind. This is a project in-of-itself.
Second, when we do the kind of large-scale science that automation is best at supporting - say testing 10,000 different formulations in a chemical reaction - it's hard to know what the data really means. This great paper from a team at Google discusses all the ways that data fails us when it comes from automated systems that we don't totally understand. This problem is exacerbated when we solve these problems with one-off, ad hoc solutions, because that piles on additional reproducibility issues.
We can fix this by setting integration standards that everyone building any part of the toolchain can conform to. This solves the first issue by making integration a single standard problem, instead of many unique problems that you have to discover anew each time. It solves the second issue by empowering the people most familiar with the science to build the tools that execute experiments.
This post proposes a framework for such a standard. I'm focusing on data and control systems here, but I think this standard should also include a physical integration framework describing how to physically connect things - or be partnered with a standard that does.
The 8-Layer DIP Framework
At a high level, the framework defines the layers of abstraction - not the implementation details. If done right, each layer is modularized away from the other layers, making problems that arise on implementation only a problem within the scope of that layer. Each layer can be built by different people, and you can mix-and-match them to meet the needs of your application.
I count 8 layers required to get the level of modularity that is useful. So, to be cute, I've called it the 8-Layer Dynamic Integration Protocol (DIP) Framework. I'm not married to the name.

Please, try out the 8-Layer DIP I've made:
- Workflow Definition Layer
- This is a language to define what should happen on an automated system. It is represented as a static, storable, transferable text object. There are many possible implementations, but as long as it results in reproducible workflows represented by a static, storable transferable text object, it works.
- Simulation Layer
- This is a set of tools to check capabilities. It may also attempt to predict and/or visualize outcomes of the program running, depending on the implementation of the simulator.
- You could call this a Digital Twin.
- Command Layer
- Human UI, exposes all systems and their capabilities. "Capabilities" includes kicking off a pre-programmed process as well as a manual process, and necessary interrupts.
- Execution Layer
- Responsible for maintaining and reporting overall system state. This is "right now" state. The Execution layer doesn't have the responsibility of tracking history, as I feel that would be overloading responsibilities for no reason. The Execution layer could kickoff a history-tracking process.
- It is also responsible for creating and destroying orchestration objects as necessary. This is necessary because the automation tools are physical things that have a state independent of the software, as is the lab that the automation tools are in, but the fact that all the tools are working together is short-lived and its state is fully virtual. So this layer provisions virtual systems that can bridge this divide.
- Orchestration Layer
- This layer is responsible for translating high-level commands into low-level orchestration logic that devices and meta-devices can respond to. Must be able to set up relationships between devices and command them as necessary.
- Additionally, it must receive manual commands from the command layer.
- Finally, it it must report back to the logging layer.
- Meta-Device Layer
- A grouping methodology to allow many devices to work together and communicate as one device over the network. This is necessary because many physically-connected sets of devices share drivers on one set of silicon.
- For example, an Opentrons liquid handling robot can both pipette and operate their magnetic bead module, which are different enough that it's confusing to try to jam them into one device object.
- Device Layer
- Responsible for actual sensing and actuation. It must report its capabilities when queried, as well as any sensing or feedback data that the device is designed to report.
- Logging Layer
- Responsible for journaling all activity reported over the network so that it can be reassembled later for analysis and troubleshooting. Logs can be reported in batch or real-time, depending on implementation.
- This layer should also produce an execution report in a file-like format that can be compared to the Workflow Definition file described above.
Here's the diagram again, with some shorthand commentary:

Using This To Build Better Automation Together
The goal is to build stuff with this framework, change it in ways that make it better, then build even better stuff with it.
But this is in the early phases of development. There are a handful of frameworks and standards that seem like they're on the right track, and could be complimentary to 8-Layer DIP. SiLA2, MTP, O-PAS, ISA-88, ISA-95, and Allotrope all come to mind. I'd like to understand how they all fit together, and avoid inventing yet another standard. I plan to keep exploring what lab and industrial automation execution models are in practice today in future blog posts.
I'm open to feedback on this framework. Here are some questions I have:
- What else am I missing?
- What use-cases does this approach not cover?
- What assumptions have I accidentally made that will cause me future trouble?
- What scaling, robustness, and security issues should we look out for?
If you have any comments, arguments, or cutting counter-proposals, my email is tim@bioartbot.org.
BONUS: The Requirements
Here are the requirements I'm working from to build this framework. These assumed requirements should be checked upon implementation.
The open-source integration framework must:
- Allow collection of devices to be orchestrated so that they all act to carry out a single objective.
- Allow devices to be collected into arbitrary groups, so that they can be used as building blocks for higher-level devices.
- Describe a way for devices to be connected to - and communicate in real-time with - an orchestration system.
- Include a machine-readable way to describe a device's functionality. This has to work across a broad set of device types and applications.
- Describe a static format to store and recreate orchestrated device relationships, like, for instance, a Dockerfile.
- Describe a static format to store and recreate system instructions - e.g. "Move left 100mm", etc.
- Set expectations for how such static format files are deployed onto a physical system.
- Provide a model for how to talk about both what should be done (according to the static format above) and what was done.
I've also written a couple of constraints:
- The communication method chosen between devices should allow response times under 100ms[1]
- The standard should minimize assumptions about the working domain. Because of this, definitions need to be extensible and composable - I need to be able to build descriptions of capabilities and objects from primatives included in the standard.
BONUS 2: Example Using the Framework
I want to walk through an example of a system using these layers. This is just one application, but hopefully it gives a sense of how each of these layers may interact in practice.
I'm trying to imagine a solution that applies broadly, but I want to test it against a specific problem so we can be sure it solves it. For me, that's the BioArtBot project I've been working on for the past few years.
BioArtBot uses automation to expand access to biological science. Users draw a picture, and a robot reproduces that drawing with colorful microbes, resulting in a growing, living drawing. I based it off the low-cost Opentrons 2, but one of the barriers I've faced with it is that the Opentrons 2 is only so cheap - I can't expect every library and community center to have one. There are cheaper alternatives with fewer features (and more expensive robots with more features), but I can't support scripts for all of them.

I'd like to be able to generate one high-level script for making a microbial art piece and deploy it to everything from a $75 DIY XY-plotter to a $1M integrated biofoundry. Then I want someone using the platform to invent a new kind of device that's better than both of them at some artistic technique I hadn't thought of.
So let's talk about how this framework would work for BioArtBot. I'm going to assume, for the sake of example, that I've two setups that I want to use:
- A Jubilee using a 3D-printing tool to distribute the liquid culture
- A Clank modular CNC, with a Pipettin pipette attached to it
From one print file, I want both of these to print the same picture.
First I set everything up. I define the Jubilee, Clank, and Pipettin pipette as devices, then I connect the Pipettin pipette to the Clank. Because, in this hypothetical, both systems confirm to our communication specification, the Pipettin reports its capabilities to the Clank OS. Now we have two meta-devices:
- The Jubliee meta-device, which comprises the Jubilee motion controller and the 3D printing tool.
- The Clank meta-device, which comprises the Clank motion controller and the Pipettin pipette.
Finally, I configure both meta-devices to register themselves with my Execution Layer server, which I hypothetically have running on the lab network. That way they show up when I look for them from the Command Layer. [2]
Now that the systems are set up, I write my program, using the Workflow Definition Layer. In the BioArtBot case, this is handled by the BioArtBot UI, with some help from the backend to translate the instructions into a text object. But instructions could be manually written in an IDE, or with Python if someone wanted to develop a different print style.
Next I use my laptop's browser to connect to the Command Layer to look at my available devices. When I see my device - let's say it's the Clank - I select it and send it the Workflow file. At this point, the Command Layer sends the workflow to the Execution Layer, which passes it and the reported capabilities of the Clank to the Simulation Layer[3].
The Simulation Layer performs analysis on the Workflow and confirms that the Clank can do every command that the Workflow contains. It's aware of the Clank's capabilities because they were registered in my initial setup. If everything checks out, the Simulation Layer sends an OK status back to the Execution Layer, which proceeds to create an Orchestration object on the designated server.
The Orchestration object is a real-time processor that gets created on a server for the length of the workflow execution. When it's created, it knows that it needs to establish a connection with the Clank and send it the movement instructions. Assuming no errors happen in this connection, it triggers the Workflow on the Clank.
The Clank knows how to operate the Pipettin device, because its been configured as a meta-device, so it can pass the dispense operations directly down the pipette. As the Clank operates, it streams any operations it performs or measurements it takes back to the Orchestration Layer.[4] The Orchestration aggregates all of this operations data and passes it to the Logging Layer.
Once the Orchestration Layer receives confirmation that the final step of the workflow is complete, it sends a log message that it is complete to the Logging Layer, then resets its status as "Available" with the Execution Layer.
I check in on my workflow's progress when I have time and the Command Layer queries the most recent run in the Logging Layer - I get a full log of operations that occurred, and I can link them back to the original submission from the website so I can send the results to the submitter. Cool!
Rinse and repeat for the Jubilee. I compare my two logs against each other and see that they differed from each other in a implementation - the Jubilee 3D printer directly pumps liquid culture onto the plate, while the Clank/Pipettin has to aspirate material first. I check my physical results and see that the prints look pretty similar, although I see more variance in the "pixel" size with the 3D printer.
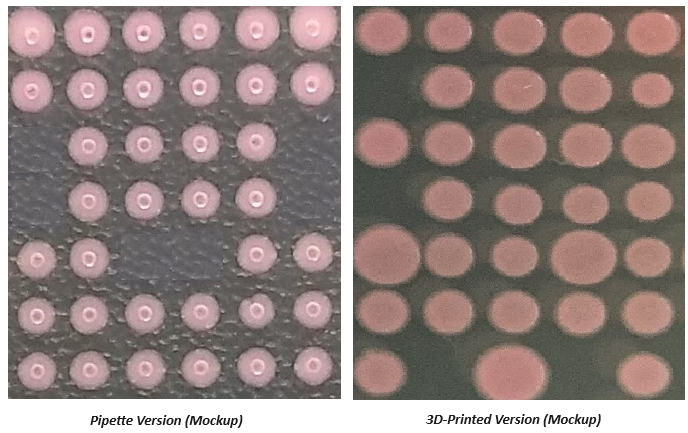
Given that, as a kindness to future implementers of the same protocol, I publish these two implementations as functionally equivalent for my application in a public repository. I note each methods observed pixel-size variance, in case someone wants to implement these protocols in a different context.
Comparing outcomes like this is useful feedback - and ultimately necessary, because it brings scientific empiricism into what would otherwise just be assemblies of logic. This is what closes the loop to push automated science forward.
I don't know if this is really the right timeframe - I wanted something that would force the system to be responsive enough to not cause major issues on robotic crashes, over-pressurization, or overheating. The idea is that if you're going to do this distributed networked approach, you need to be mindful about round-trip time for signals in the system. ↩︎
Incidentally, with a little network management, the Execution layer could run entirely on the cloud and serve many different physical spaces. But this creates a lot of other headaches (see footnote #1), so probably best to only do it this way if there's a real advantage. ↩︎
The Command Layer could also expose an API so that the BioArtBot website triggers a command automatically when someone submits to the website. Then they could see their art printing in real-time. Neat! ↩︎
This approach works whether the Orchestration Layer is streaming each instruction to the Clank one at a time, or if it sends all of the instructions in a batch. The only thing that matters is synchronicity of devices, so multiple-device configurations, devices need to be told to wait for confirmation if necessary. ↩︎